
- August 10, 2023
- Posted by: team SOUTECH
- Category: Blog, Data Analysis and Virtualization, Data Science Free Training, Softwares, Technologies
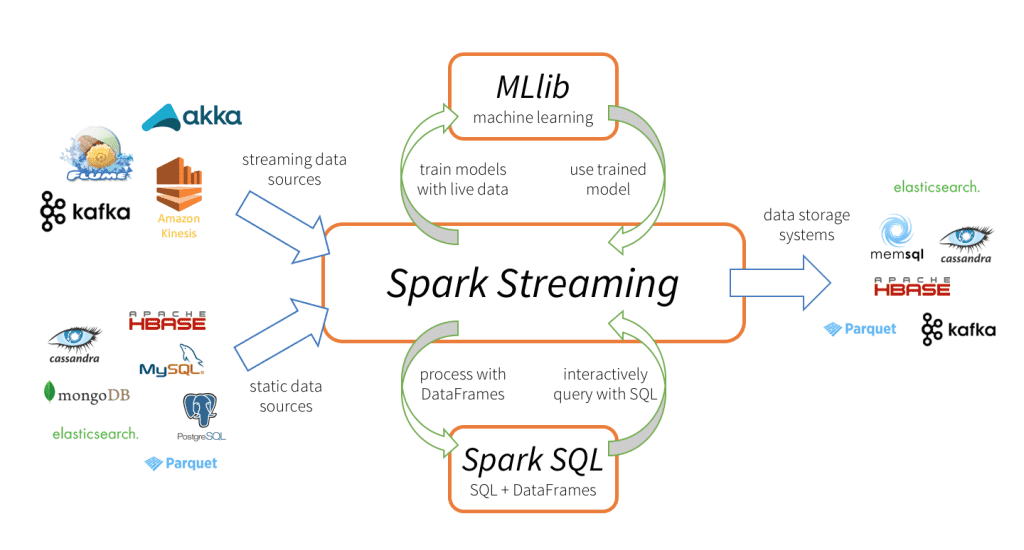
Introduction: Apache Spark has emerged as a powerful open-source distributed computing framework that revolutionizes the way big data is processed and analyzed. With its ability to handle large-scale data processing in a distributed and fault-tolerant manner, Spark has become the de facto standard for big data analytics. In this article, we will delve into the world of Apache Spark, understand its core concepts, and explore how it addresses the challenges posed by big data processing.
Section 1: Understanding Apache Spark
– Introduction to distributed computing: Explaining the need for distributed frameworks in big data processing.
– Spark’s architecture: Understanding the master-worker architecture and how tasks are distributed across the cluster.
– Resilient Distributed Datasets (RDDs): The fundamental data structure in Spark that enables fault tolerance and distributed processing.
Section 2: Spark Core Components
– Spark SQL: Integrating SQL queries with Spark for structured data processing.
– Spark Streaming: Real-time data processing and stream analytics with micro-batch processing.
– Spark MLlib: The machine learning library of Spark for scalable and distributed machine learning tasks.
Section 3: Big Data Processing with Spark
– Data loading and transformation: Reading data from various sources like HDFS, S3, and databases and performing transformations.
– Spark transformations and actions: Understanding transformations like map, filter, and reduce, and actions like count, collect, and save.
Section 4: Resilience and Fault Tolerance
– Fault tolerance in Spark: Exploring how Spark ensures data resilience and task recovery in case of failures.
– Data partitioning and shuffling: Understanding the techniques used to optimize data movement across the cluster.
Section 5: Spark Ecosystem and Integration
– Spark on YARN: Deploying Spark on Hadoop YARN to take advantage of Hadoop’s resource management.
– Integration with Apache Hive and Apache HBase: Utilizing Spark’s capabilities with other popular big data tools.
Section 6: Real-world Applications and Case Studies
– Large-scale data processing: Using Spark for batch processing of massive datasets, such as log analysis and sensor data.
– Stream processing and IoT: Leveraging Spark Streaming for real-time analytics in Internet of Things (IoT) applications.
– Machine learning at scale: Applying Spark MLlib for distributed machine learning on massive datasets.
Section 7: Performance Optimization and Best Practices
– Data partitioning and caching: Optimizing Spark jobs for better performance through data partitioning and caching.
– Memory management: Configuring Spark’s memory settings for efficient execution of tasks.
– Data locality: Maximizing performance by ensuring tasks run on nodes where data resides.
Conclusion:Apache Spark has become a game-changer in the big data landscape, enabling organizations to process and analyze vast amounts of data with speed and efficiency. Its scalable and fault-tolerant architecture, combined with its rich ecosystem, makes Spark a go-to choice for big data processing and analytics. By understanding Spark’s core principles and leveraging its extensive capabilities, data engineers and analysts can unlock the true potential of big data and drive transformative insights across industries.
Related posts:
 “Game On: Elevating Sports Excellence through Data Science and Analytics”
“Game On: Elevating Sports Excellence through Data Science and Analytics”
 Lexicon Alchemy: Transforming Language into Intelligence with Natural Language Processing (NLP)
Lexicon Alchemy: Transforming Language into Intelligence with Natural Language Processing (NLP)
 Sculpting Intelligence: Mastering Support Vector Machines for Supervised Learning Excellence
Sculpting Intelligence: Mastering Support Vector Machines for Supervised Learning Excellence
 Ethics Unveiled: Navigating Data Privacy and Responsibility in the Age of Innovation
Ethics Unveiled: Navigating Data Privacy and Responsibility in the Age of Innovation